|
Biodiversity Data Journal : General research article
|
Trends in access of plant biodiversity data revealed by Google Analytics
|
Corresponding author: Timothy Mark Jones (tjone54@tigers.lsu.edu)
Academic editor: Andreas Beck
Received: 21 Aug 2014 | Accepted: 04 Nov 2014 | Published: 11 Nov 2014
© 2014 Timothy Mark Jones, David G. Baxter, Gregor Hagedorn, Ben Legler, Edward Gilbert, Kevin Thiele, Yalma Vargas-Rodriguez, Lowell E. Urbatsch.
This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0) which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Jones T, Baxter D, Hagedorn G, Legler B, Gilbert E, Thiele K, Vargas-Rodriguez Y, Urbatsch L (2014) Trends in access of plant biodiversity data revealed by Google Analytics. Biodiversity Data Journal 2: e1558. doi: 10.3897/BDJ.2.e1558
|

|
Abstract
The amount of plant biodiversity data available via the web has exploded in the last decade, but making these data available requires a considerable investment of time and work, both vital considerations for organizations and institutions looking to validate the impact factors of these online works. Here we used Google Analytics (GA), to measure the value of this digital presence. In this paper we examine usage trends using 15 different GA accounts, spread across 451 institutions or botanical projects that comprise over five percent of the world's herbaria. They were studied at both one year and total years. User data from the sample reveal: 1) over 17 million web sessions, 2) on five primary operating systems, 3) search and direct traffic dominates with minimal impact from social media, 4) mobile and new device types have doubled each year for the past three years, 5) and web browsers, the tools we use to interact with the web, are changing. Server-side analytics differ from site to site making the comparison of their data sets difficult. However, use of Google Analytics erases the reporting heterogeneity of unique server-side analytics, as they can now be examined with a standard that provides a clarity for data-driven decisions. The knowledge gained here empowers any collection-based environment regardless of size, with metrics about usability, design, and possible directions for future development.
Keywords
Biodiversity, big data, herbarium, Google Analytics, botany, museums, vascular plants, systematics, taxonomy, collections, digitization, web development, Kingdom Plantae
Introduction
Herbaria are natural history museums that preserve collections of millions of specimens that offer a well established distributional model for a large-scale taxon (
The goal of this manuscript is twofold: to provide recommendations for current information managers and developers concerning the user interface and experience; and to provide a picture about the possible directions to take for those in-charge of the creation of information at all levels. Online plant databases can facilitate the democratization of botanical information through their availability, via open information that exceeds the speed of retrieval from a cabinet or bookshelf. Specimens, including type specimens, no longer need to be shipped back and forth across the globe; thereby limiting wear and tear to these important biodiversity objects while eliminating shipping costs. And importantly, all researchers can now share equal access globally, without travel, to a well established model at kingdom level (
Understanding how taxonomic resources now provided via the World Wide Web (WWW) are used, represents a new challenge. For this reason, presented here are collected data obtained from contributors using Google Analytics that functioned as a standard report (
Latest user analytics
We selected GA for website usage analytics for multiple reasons: 1) It is free to use, so is widely adopted, 2) It is standardized so analytics can be compared across institutional users, and 3) GA only tracks human usage, as opposed to most server-side analytics programs which track human and robot traffic indiscriminately.
In order to be tracked, Google Analytics requires the inclusion of a snippet of Javascript (JS) (
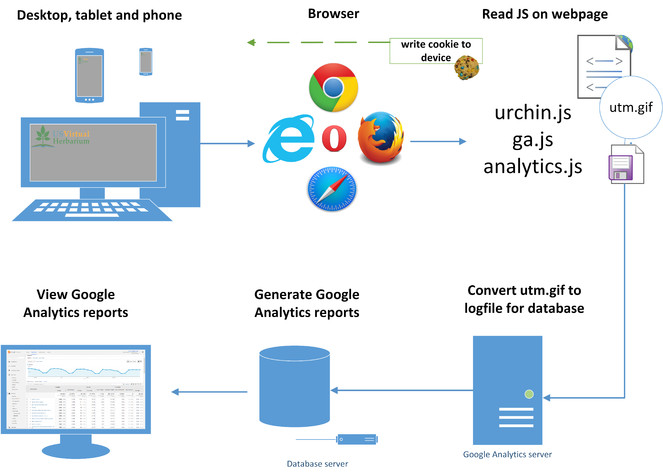
What is Google Analytics?
A user directs a browser to a website that contains a tracking code. This tracking code or script leverages the information already being gathered by the browser; but then also writes a cookie back to the device that yields additional information that the browser cannot provide, such as time-on-site or page-views. The packaged set of collected data is then sent back to a Google server in the form of a GIF file. Lastly, the GIF file is then interpreted and incorporated into reports.
Material and methods
Sites were selected for this study by searching Hyper Text Markup Language (HTML) source code of biodiversity websites for the presence of Google Analytics. After identifying sites of interest, Jones contacted curators, directors, and developers via email or phone. This process led to the inclusion of fifteen sites (
Participants and their start dates.
| Project | GA Start date | Participants | Website | Tracked analytic |
|---|---|---|---|---|
| Consortium of California Herbaria (CCH) | 2-May-07 | 30 | ucjeps.berkeley.edu | UA-1304595-1 |
| Consortium of North American Bryophyte Herbaria (CNABH) | 1-Jul-12 | 62 | bryophyteportal.org | UA-50594803-2 |
| Consortium of North American Lichen Herbaria (CNALH) | 17-Jul-12 | 59 | lichenportal.org | UA-50594803-1 |
| Consortium of Pacific Northwest Herbaria (PNW) | 20-Aug-11 | 24 | pnwherbaria.org | UA-29550699-1 |
| Cooperative Taxonomic Resource for American Myrtaceae (CoTRAM) | 8-May-11 | 5 | cotram.org | UA-19854426-5 |
| eFlora | 24-Oct-09 | 1 | efloras.org | UA-3783322-15 |
| FloraBase | 24-Aug-11 | 1 | florabase.dpaw.wa.gov.au | UA-25269128-1 |
| Global Biodiversity Information Facility (GBIF) | 28-Jun-13 | 172* | gbif.org | UA-42057855-1 |
| Herbario Virtual Austral Americano (HVAA) | 8-May-11 | 5 | herbariovaa.org | UA-19854426-4 |
| Jepson eFlora (Jepson) | 18-Nov-11 | 1 | ucjeps.berkeley.edu | UA-43909100-1 |
| Louisiana State University Herbarium Keys (LSU Keys) | 24-Aug-08 | 1 | herbarium.lsu.edu/keys | UA-1414632-44 |
| Offene Naturführer (ON) | 6-Nov-11 | 1* | offene-naturfuehrer.de | UA-27110487-1 |
| Orowiki | 6-Nov-11 | 1 | orowiki.org | UA-27158322-1 |
| Southwest Environmental Information Network (SEINet) | 19-Nov-10 | 87 | swbiodiversity.org | UA-19854426-1 |
| Tropicos | 25-Mar-08 | 1 | tropicos.org | UA-3783322-3 |
Data resources
A total of four types of GA resources are charted (
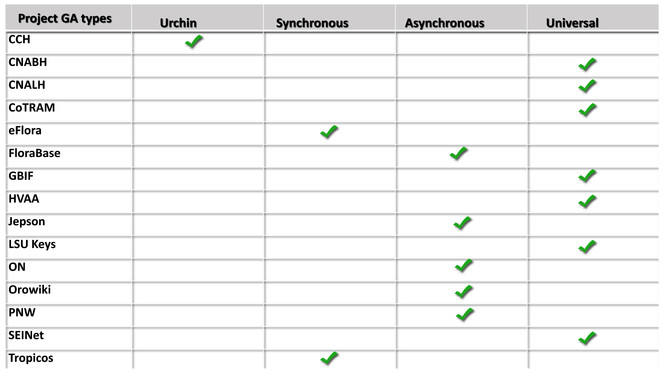
Four variants of GA are represented in this study. Urchin is the first iteration of GA, derived from software developed by Urchin Software acquired by Google in 2005. It is unique in that it employed multiple means of information gathering, using both server logs and multiple cookies. The second iteration, synchronous or traditional, released in late 2007, also used multiple cookies, plus required that the JS load in a linear fashion. Penalizing content over tracking. Asynchronous came out two years later, and allowed for faster loads of content as the webpage loads first, and GA JS loads post-content delivery. The latest variant, universal, addresses issues with mobile and the internet-of-things (emerging wearable devices and existing household appliances that can communicate via the web), as it can assimilate into reports any device that can contact a server.
Results
Number of sessions – 17,198,976 sessions from inception (when each organization began tracking) were found across the 15 GA numbers (
One year of use, across all sites from June 01, 2013 to June 01, 2014, showing over 4.5 million sessions.
| Project | Sessions | Average Page Views | Average User Duration (min) |
|---|---|---|---|
| CCH | 73508 | 7.7 | 10:41 |
| CNABH | 11164 | 3.98 | 5:35 |
| CNALH | 59138 | 2.74 | 3:54 |
| CoTRAM | 3630 | 2.33 | 1:59 |
| eFlora | 1131425 | 4.68 | 4:30 |
| FloraBase | 388838 | 9.55 | 8:44 |
| GBIF | 709036 | 3.99 | 3:07 |
| HVAA | 5403 | 2.29 | 1:35 |
| Jepson | 121891 | 5.79 | 8:35 |
| LSU Keys | 7329 | 3.83 | 4:38 |
| ON | 164788 | 1.88 | 1:41 |
| Orowiki | 6259 | 4.91 | 4:03 |
| PNW | 24247 | 5.96 | 7:46 |
| SEINet | 235603 | 4.87 | 5:46 |
| Tropicos | 1638764 | 11.32 | 12:07 |
Stable bounce rates – Bounce is defined as the user visiting the primary page only and then exiting. Bounces are not included across the statistics, as they are treated as zeros. All participants in the study show relatively stable bounce rates. See discussion (
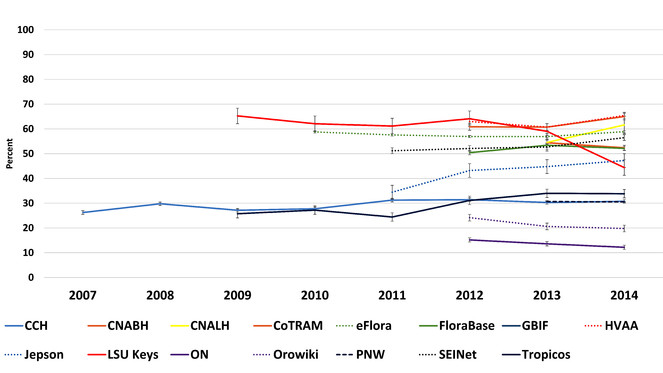
Historical bounce rates of study participants as compared year by year from January 01 to January 01 (
Operating systems – Revealed five major operating systems: Windows, Macintosh, Linux, iOS, and Android (
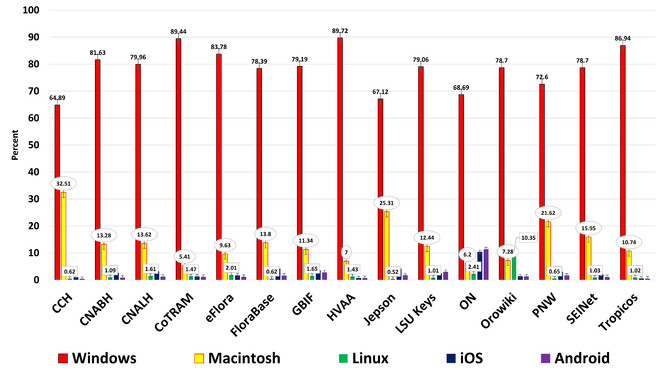
Historical operating systems to January 01, 2014 (
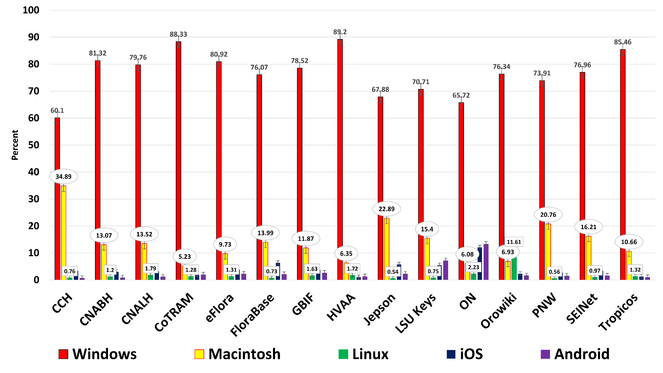
One year of operating systems from January 01, 2013 to January 01, 2014, showing same ON trend (
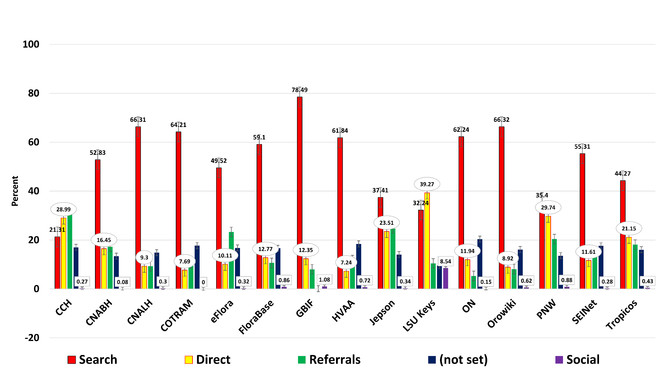
Yearly traffic* broken down by search, direct, referral, 'not set', and social (
Outreach – Each site's traffic favors its country of origin but all nations, territories, and/or commonwealths are represented across the sample (
Long-term outreach in countries, cities, and networks across variable project start dates through June 01, 2014.
| Project | Countries | Cities | Networks |
|---|---|---|---|
| CCH | 148 | 5228 | 8935 |
| CNABH | 124 | 3090 | 3228 |
| CNALH | 175 | 6891 | 8015 |
| CoTRAM | 134 | 1614 | 1969 |
| eFlora | 238 | 28738 | 109754 |
| FloraBase | 222 | 12558 | 23415 |
| GBIF | 234 | 17725 | 36097 |
| HVAA | 137 | 2309 | 2951 |
| Jepson | 188 | 7361 | 10376 |
| LSU Keys | 135 | 3514 | 3577 |
| ON | 144 | 5179 | 10330 |
| Orowiki | 143 | 2689 | 3651 |
| PNW | 110 | 2282 | 2090 |
| SEINet | 223 | 16950 | 32305 |
| Tropicos | 238 | 23923 | 68509 |
One-year outreach in countries, cities, and networks from June 01, 2013 to June 01, 2014.
| Project | Countries | Cities | Networks |
|---|---|---|---|
| CCH | 95 | 1794 | 1982 |
| CNABH | 110 | 1990 | 1981 |
| CNALH | 164 | 5303 | 5864 |
| CoTRAM | 100 | 861 | 999 |
| eFlora | 230 | 20569 | 41826 |
| FloraBase | 211 | 8030 | 11659 |
| GBIF | 234 | 17725 | 36097 |
| HVAA | 114 | 1128 | 1366 |
| Jepson | 175 | 5533 | 6933 |
| LSU Keys | 108 | 1660 | 1477 |
| ON | 117 | 4104 | 6641 |
| Orowiki | 118 | 1620 | 1878 |
| PNW | 105 | 1915 | 1693 |
| SEINet | 209 | 11204 | 15756 |
| Tropicos | 229 | 16172 | 30531 |
Mobile growth – Phone & tablet usage is steadily increasing for all resources (
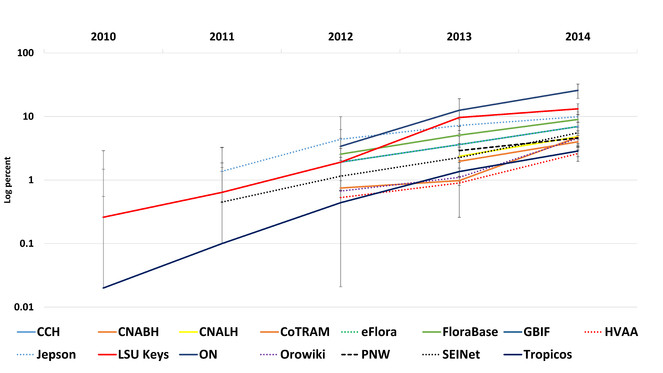
Combined phone and tablet usage by percentage at log, showing emergence of mobile in 2010 in a changing landscape of device use (see
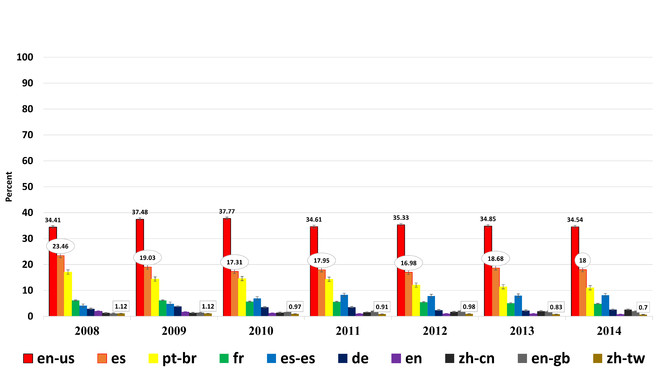
Ten top International Organization for Standardization (ISO) languages in use at Tropicos over six years; in order of percentage of usage (
- en-us English of U.S.A.
- es Spanish
- pt-br Portuguese of Brazil
- fr French
- es-es Spanish of Spain
- de German
- en English
- zh-cn Chinese simplified
- en-gb English of Great Britian
- zh-tw Chinese of Taiwan
Device types – The number of different device types has grown exponentially in recent years, from just a few types in 2010 to over 1500 in 2014 (
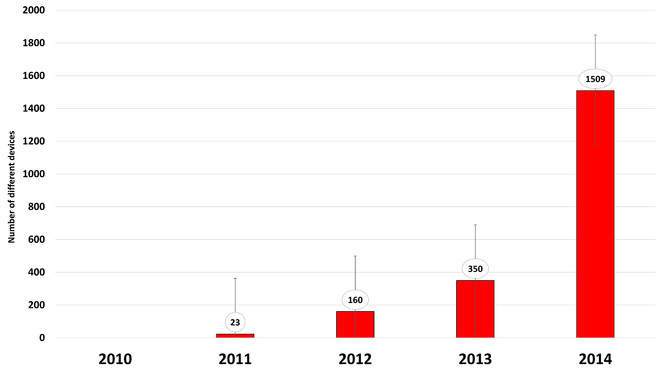
Tropicos showing the exponential growth of mobile device types over a five year period (
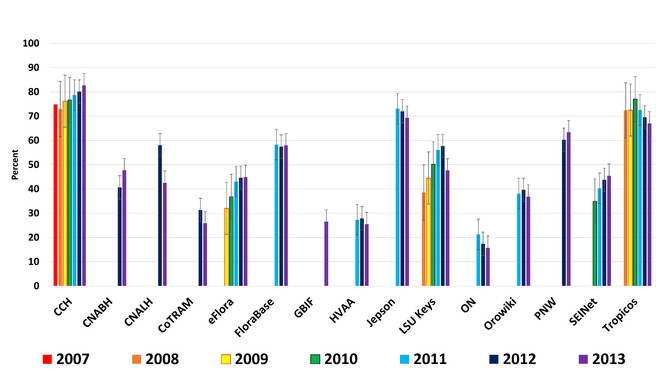
Consistent pattern of usage over seven years of returning users for each resource (
Browser Wars – Five web browsers are in a slow-motion-knife-fight for dominance (
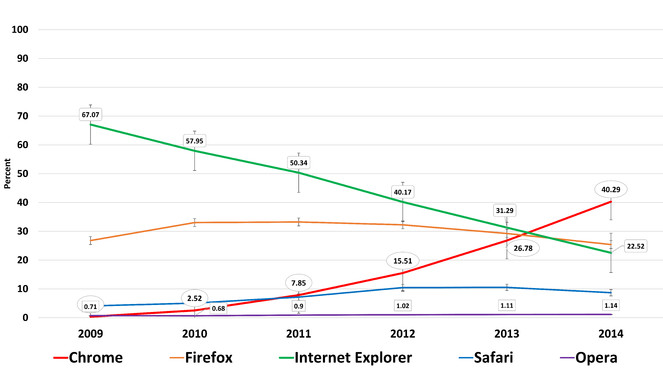
Browsers and their design are vital to how we interact with the WWW. Browser usage at Tropicos from 2009 reveals a changing landscape in the user base of of browsers. This same trend is seen at CCH, eFlora, LSU Keys, and SEINet. Nostalgically and historically, the Netscape browser is also noted in these data at a high of two percent (
Search, Direct, Referrals, and Social – Traffic types were examined in a one year study (
Language – Tropicos demonstrated relatively stable language usage across the user base. With the dominate languages noted being English, Spanish, Brazilian Portuguese, French, German, and Chinese (
Returning Visitors Vs. New Visitors – Consistent usage demonstrated a stable regime of returning plant biodiversity data consumers (
Discussion
Reinvention and re-purposing of traditional materials have enabled disciplines surrounding plant biodiversity to grow online, as these types of data are ideally suited for the web (
271 years total-session-time in seven years. Total user duration time yields 271 years since inception. Derived by sessions multiplied by the avg time to yield years of usage. *Caveats: those denoted by asterisks are sub-sampled by GA, so it is a population that is sub-sampled due to scale.
| Project | Sessions | Average User Duration (seconds) | Total Duration (years) |
|---|---|---|---|
| CCH | 433964 | 650 | 8.9 |
| CNABH | 21880 | 237 | 0.17 |
| CNALH | 104933 | 233 | 0.78 |
| CoTRAM | 10457 | 136 | 0.05 |
| eFlora* | 5337830 | 233 | 39.43 |
| FloraBase* | 1233942 | 423 | 16.6 |
| GBIF | 803552 | 248 | 6.3 |
| HVAA | 17819 | 105 | 0.07 |
| Jepson | 276009 | 561 | 4.9 |
| LSU Keys | 25732 | 270 | 0.2 |
| ON | 410910 | 103 | 1.2 |
| Orowiki | 16534 | 308 | 0.2 |
| PNW | 38216 | 484 | 0.6 |
| SEINet | 740129 | 295 | 6.9 |
| Tropicos* | 7486692 | 778 | 184.7 |
| Total time | 271 Years |
How a session is determined – A session is started after a browser requests a tracked webpage. On each, time spent and page views are recorded via a cookie (on desktops, or 90% of this data). By default, each session will expire after thirty minutes. If the user does not progress to another page, it is recorded as a bounce. For example, a researcher clicks on webpage, and then decides to eat lunch for thirty minutes, without clicking on anything after visiting the site. This would count as a 30 minute session, right? No, because they bounced.
Bounce rate – Bounces are not recorded as sessions since the user did not progress through the site after visiting the first page. For example, the same researcher uses the identical website again after lunch for 30 seconds, does a search for Carex aurea, which returns a results page. This results page further links to data-based specimen images which the researcher importantly clicks on. Three clicks and pages into the site now with a good broadband connection. Immediately upon instantiation of the third page, the researcher gets a phone call that lasts for 30 minutes. Here, due to the progression over three different web pages (two pages would count too), the session counts. And a bonus dwell time of 30 minutes is recorded in the report. While the actual session lasted only ~30 seconds. Nevertheless, total duration of a session remains informative because it allows for comparison, albeit a somewhat blurry picture of what is actually happening due to the lunch problem. So, progression is the key to a session, as those that do not progress do not count. This possibly skews overall results downwards, especially for those serving one-page websites such as blogs or apps.
Did that latest upgrade really do anything? – Additionally, when a user clicks on a directed event (campaign), new informational chains are instantiated. Campaigns are modifications to the JS that reveal supplementary information such as URL parameters that can identify a "web development push". FloraBase is unique in this sample, in that they are modifying their GA JS code to reveal additional parameters with their use. However, it can result in occasional double counting of sessions. This minor discrepancy is trivial when compared to the valuable information that can be gleaned from the data about the change in user behavior after an upgrade.
Bring your own device (B.Y.O.D.) or here comes mobile – 2013 was the first year that over one billion smartphones were shipped worldwide, and during this same time period only 300 million PC's were purchased (https://www.gartner.com/doc/2665319). Not so surprisingly, mobile growth has nearly doubled for the examined projects over the years examined (
Plants aren't social? – Overall, the amount of social media interaction was found to be trivial (
What not to do – While canvassing institutions for access to their GA accounts, a few unexpected issues arose concerning the administration of GA accounts:
- Not knowing who owns the GA administrator account. An understandable confusion caused by relocation or promotion of the individual that had originally set up GA for that institution years ago.
- Copying one GA code across different institutions and/or continents resulting in a global miasma of information that requires cleaning and pruning for even simple interpretation.
- Using one GA code from front-door to back-door institutionally; meaning it tracked book-your-wedding user data as well as specimen user data; as well as from the entomology department, the anthropology....
- Deploying GA code to a landing page only. To be effective, all pages require the placement of the tracking code.
- Ignoring the trends towards future mobile usage.
Many institutions still rely only on server-based tracking. This balloons the data through the inclusion of bots or spiders that constantly scour the web to index pages for search or other not-so-noble reasons. It was recently estimated that over half of all web traffic now is non-human or machine based (http://www.incapsula.com/blog/bot-traffic-report-2013.html) basically rendering those that use this server-log method to be data blind (
Next-generation of GA? – Upgrading any GA user to Universal GA, requires the replacement of GA codes on all pages being tracked. A relatively new method, that still requires a one-time total code replacement, is the use of Google Tag Manager (GTM) (http://www.google.com/tagmanager/), as the International Plant Names Index (http://www.ipni.org/) is currently doing. GTM uniquely generates a script that permits future changes by functioning as an "analytic tattoo" for a website; thereby allowing for easy updating across all the deployed pages without wholesale replacement of all scripts. The tattooed script remains the same, but the instructions to that script are mutable, allowing for coding on-the-fly, and allowing for rapid experimentation across site(s). Surely, traffic for all biodiversity based web sites would dwarf these figures for plant biodiversity sites alone. Then considering that less than five percent of all collections-based biodiversity information is now online (
Acknowledgements
The authors would like to thank Chuck Miller at the Missouri Botanical Garden, for taking the time. We would also like to thank Rod Page & Tim Hirsch for quickly providing a global dataset with Global Biodiversity Information Facility; and Corinna Gries and Les Landrum for the sharing of their GA data from their resources. Plus thanks to Barbara Thiers, of New York Botanical Garden, for the sharing of Index Herbariorum georeferenced data. Greatly appreciated are the contirbutions of Pedro Lake for the constant editing of this MS. And thank you Mary Barkworth for the discussion that started this chapter.
Author contributions
Tim Jones contacted David Baxter, Ed Gilbert, Tim Hirsch, Ben Legler, Chuck Miller, Rod Page, and Kevin Thiele, for the sharing of GA account information. David Baxter provided all information for CCH and Jepson via Google Sheets (https://docs.google.com/spreadsheets/d/19Rvea4-qtOXEUKBu3c0nEOJo2IfzbSkuQpn83x6Argg/edit?usp=sharing).
References
- National Comparative Museum Salary Study. Online PDF 1: 1. [In English]. URL: http://freshinthefield.files.wordpress.com/2012/12/2012_museum_salary_study.pdf
- Approaches to estimating the universe of natural history collections data. Biodiversity Informatics 7: 81‑92. [In English]. URL: https://journals.ku.edu/index.php/jbi/article/view/3991/3805
- ActKey: A Web-Based Interactive Identification Key Program. Taxon 54 (4): 1041. [In English]. DOI: 10.2307/25065490
- The Web at 25. Pew Research Report 1: 15‑16. [In English]. URL: http://www.pewinternet.org/files/2014/02/PIP_25th-anniversary-of-the-Web_0227141.pdf
- Evaluating information seeking and use in the changing virtual world: the emerging role of Google Analytics. Learned Publishing 27 (3): 185‑194. [In English]. DOI: 10.1087/20140304
- VertNet: A New Model for Biodiversity Data Sharing. PLoS Biology 8 (2): e1000309. [In English]. DOI: 10.1371/journal.pbio.1000309
- A comparison of interactive identification programs. URL: http://delta-intkey.com/
- The demographics of social media users, 2012. 14. Pew Research Center, Washington D.C., 14 pp. [In English]. URL: http://www.lateledipenelope.it/public/513cbff2daf54.pdf
- Using Google Analytics for improving library website content and design: a case study. LPP Special Issue on Libraries and Google 1 (1): 1. [In English]. DOI: 10.7282/T3MK6B6N
- Challenges for taxonomy. Nature 417 (6884): 17‑19. [In English]. DOI: 10.1038/417017a
- Symbiota – A virtual platform for creating voucher-based biodiversity information communities. Biodiversity Data Journal 2: e1114. [In English]. DOI: 10.3897/bdj.2.e1114
- Overview of interactive keys. Online publication. URL: http://kikforum.wordpress.com/2007/01/12/overview-of-interactive-keys-provided-by-gregor-hagedorn/
- Using Google Analytics to Evaluate the Usability of E-Commerce Sites. Lecture Notes in Computer Science. URL: https://doi.org/10.1007/978-3-642-02806-9_81 DOI: 10.1007/978-3-642-02806-9_81
- A visual identification key utilizing both gestalt and analytic approaches to identification of Carices present in North America (Plantae, Cyperaceae). Biodiversity Data Journal 1: e984. [In English]. DOI: 10.3897/bdj.1.e984
- Learning web analytics: A tool for strategic communication. Public Relations Review 37 (5): 536‑543. [In English]. DOI: 10.1016/j.pubrev.2011.09.011
- How Many Species Are There on Earth and in the Ocean? PLoS Biology 9 (8): e1001127. [In English]. DOI: 10.1371/journal.pbio.1001127
- Norwegian Natural History Museum Collection Computerization: A First Report. Collection Forum 12 (2): 55‑59. [In English]. URL: http://t.spnhc.org/media/assets/cofo_1996_V12N2.pdf#page=13
- Article-Level Metrics and the Evolution of Scientific Impact. PLoS Biology 7 (11): e1000242. DOI: 10.1371/journal.pbio.1000242
- The second digital transition: to the mobile space – an analysis of Europeana. Learned Publishing 26 (4): 240‑252. DOI: 10.1087/20130402
- Information Seeking Behaviour and Usage on a Multi-media Platform: Case Study Europeana. Library and Information Sciences. URL: http://ciber-research.eu/download/20140930-Information_Seeking_Behaviour_and_Usage_on_a_Multimedia_Platform.pdf DOI: 10.1007/978-3-642-54812-3_6
- Information on the go: A case study of Europeana mobile users. Journal of the American Society for Information Science and Technology 64 (7): 1311‑1322. DOI: 10.1002/asi.22838
- Bootstrap. 3.0. Twitter. Release date: 2013 8 09. URL: https://github.com/twbs/bootstrap
- The PhyLoTA Browser: Processing GenBank for Molecular Phylogenetics Research. Systematic Biology 57 (3): 335‑346. DOI: 10.1080/10635150802158688
- An update of the Angiosperm Phylogeny Group classification for the orders and families of flowering plants: APG III. Botanical Journal of the Linnean Society 161 (2): 105‑121. [In English]. DOI: 10.1111/j.1095-8339.2009.00996.x
- The holy grail of the perfect character: the cladistic treatment of morphometric data. Cladistics 9 (3): 275‑304. [In english]. DOI: 10.1111/j.1096-0031.1993.tb00226.x
Supplementary materials
Georeferenced list of world's herbaria
Download file (66.58 kb)
The data for all years prior to 1981 were taken from the herbarium's annual report to the Utah Agricultural Experiment Statement. Initially, only specimen growth was included in these reports. With time, we started tracking additional aspects. We have never included our GA data in the report. This is something we should have added when we first installed the software on our pages but we did not. We no longer have easy access to the web site and the GA data.
Download file (183.50 kb)
Download file (16.90 kb)
Total of page, user, and duration
Download file (9.41 kb)
Different devices used on Tropicos over the past year by model and manufacturer.
Download file (1013.55 kb)
List of herbaria and specimen numbers in respective institutions
Download file (11.95 kb)
Bounce rates by years
Download file (8.49 kb)
Years are determined by using January 01 (or start date of that year) to January 01
Download file (13.86 kb)
From January 01, 2013 to January 01, 2014
Download file (14.20 kb)
Long and short term operating systems across top-five operating systems.
Download file (20.78 kb)
Top fiver languages over time at Tropicos
Download file (202.34 kb)
2007-2008
Download file (148.19 kb)
2008-2009
Download file (185.52 kb)
Search, diirect, referrals, not set, and social
Download file (8.51 kb)
2009-2010
Download file (183.11 kb)
2010-2011
Download file (183.12 kb)
2011-2012
Download file (183.47 kb)
2012-2013
Download file (184.03 kb)
2013-2014
Download file (184.43 kb)
Browser percentage by years at Jan. 01 to Jan. 01.
Download file (10.25 kb)
Percent returning sessions.
Download file (9.82 kb)