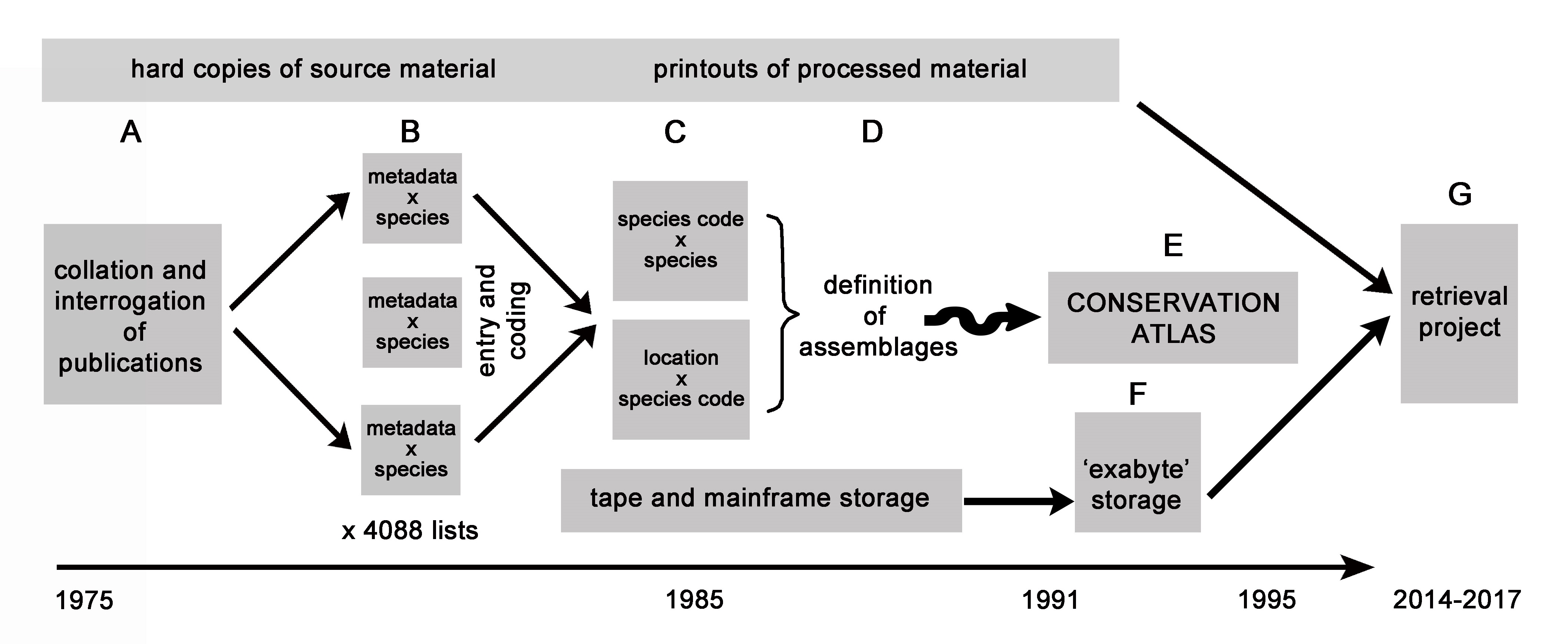
The workflow from collation of original documents (A) through the publication of the ‘Conservation Atlas’ (E) to the retrieval project (G). The first step was to extract and digitise data from written publications (A-B). Due to the computing limitations of the time, it was necessary to split the data into sub-files (B and C) for analysis (D) which was the aim of the original project ('The Conservation Atlas' 1975-1995). Storage throughout the Conservation Atlas project was in both hard copy printouts and digital form. The ‘mainframe’ computers referred to were those from the PDP-10 computer family through the University of Queensland computer centre. The magnetic tapes were used as backup storage from the PDP-10s and the Exabyte tape was used to store the data from the magnetic tapes at the end of the Conservation Atlas project.
Note: Letters are used to facilitate reference to the figure from the text. The temporal axis is not to scale.