|
Biodiversity Data Journal :
Research Article
|
|
Corresponding author: A. Townsend Peterson (town@ku.edu)
Academic editor: Vincent Smith
Received: 21 May 2018 | Accepted: 17 Oct 2018 | Published: 07 Nov 2018
© 2018 A. Townsend Peterson, Alex Asase, Dora Canhos, Sidnei de Souza, John Wieczorek
This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation:
Townsend Peterson A, Asase A, Canhos D, de Souza S, Wieczorek J (2018) Data Leakage and Loss in Biodiversity Informatics. Biodiversity Data Journal 6: e26826. https://doi.org/10.3897/BDJ.6.e26826
|
|
Abstract
The field of biodiversity informatics is in a massive, “grow-out” phase of creating and enabling large-scale biodiversity data resources. Because perhaps 90% of existing biodiversity data nonetheless remains unavailable for science and policy applications, the question arises as to how these existing and available data records can be mobilized most efficiently and effectively. This situation led to our analysis of several large-scale biodiversity datasets regarding birds and plants, detecting information gaps and documenting data “leakage” or attrition, in terms of data on taxon, time, and place, in each data record. We documented significant data leakage in each data dimension in each dataset. That is, significant numbers of data records are lacking crucial information in terms of taxon, time, and/or place; information on place was consistently the least complete, such that geographic referencing presently represents the most significant factor in degradation of usability of information from biodiversity information resources. Although the full process of digital capture, quality control, and enrichment is important to developing a complete digital record of existing biodiversity information, payoffs in terms of immediate data usability will be greatest with attention paid to the georeferencing challenge.
Keywords
biodiversity data, usability, fitness for use, time, place, taxon, informatics, geographic referencing, georeferencing, digitization
Introduction
NOTE: responses to longer-form commentaries from reviewers are provided in Suppl. material
Biological diversity is the variety of life on Earth, and provides or sustains, at least in an ultimate sense, all raw materials for human well-being (food, water, shelter). Biodiversity also supports a series of ecosystem services that, although perhaps less tangibly, maintain all natural and human systems (
Primary biodiversity data—i.e., data records that document the occurrence of a particular species at a place at a point in time—represent a central element in the universe of data documenting biodiversity. Primary biodiversity data have many applications, including documenting basic biodiversity patterns (
Still, total numbers of primary biodiversity data records that are openly available as digital accessible knowledge (DAK;
Even with more than a billion biodiversity specimen and observational data records existing and available in digital format (as of 22 July 2018), many of those records are compromised by missing, partial, or incomplete information, such that they are not usable in many science applications. We term this process as data leakage, or data attrition, to emphasize how an initially large data resource is reduced massively via a series of seemingly relatively minor factors (this view of leakage contrasts with a more temporal sequence of degradation or loss;
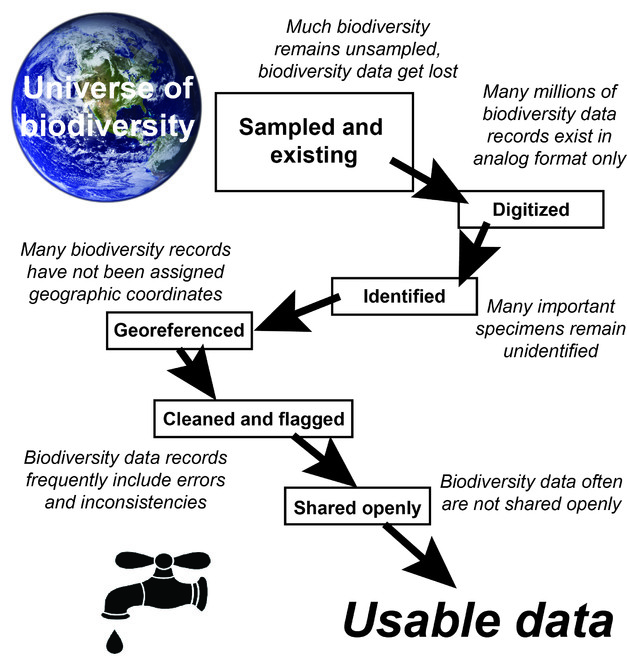
Schematic summarizing the translation between biodiversity and biodiversity data, and how those data “leak,” and get lost and degraded, such that only a small subset is available as usable data for science and policy applications. Note that the particular sequence of steps is not set, and may indeed vary significantly from region to region, taxon to taxon, or source to source.
In this contribution, we explore the dimensions and magnitude of these data leaks. Using a diverse suite of plant and bird collections as examples, we assess numbers of data records for which information on time, place, and taxon that is missing or incomplete, distinguishing between data that are simply lacking and those that can be added or rescued. We also explore joint effects that relate directly to two typical uses of such data: place x taxon, for ecological niche modelling and species distribution modelling (
Material and methods
Our analysis sequence is outlined in a protocol file. Briefly, though, we downloaded full institutional datasets for ornithological collections from VertNet (
Each record from each data set was analyzed with respect to time (i.e., in Darwin Core terms, day, month, year, verbatimEventDate), taxon (genus, subgenus, specificEpithet, infraspecificEpithet, taxonRank), and place (country, stateProvince, county, municipality, locality, verbatimLocality, decimalLatitude, decimalLongitude, coordinateUncertaintyInMeters, coordinatePrecision, verbatimCoordinateSystem, georeferenceProtocol). We evaluated each data record as regards 4 categories of completeness and fitness for use: information missing completely (accorded value 0), information partial (value 1), information incomplete but with sufficient information that it could be “rescued” and brought to completeness (value 2), and information complete and ready for use (value 3). We deemed information as “rescuable” when information can be improved or corrected, such as by georeferencing textual geographic information quantitatively, or by correcting a scientific name that is not a standard name; however, we take a somewhat restrictive view of potential for rescue, in that we do not include as rescuable those specimens that could be reexamined physically to obtain information not in the digital record--rather, we focus on rescue in the sense of the data record per se.
Data on time were considered to be partial when information on day, month, year, or their equivalent in eventDate was missing; time was considered as rescuable when full information appeared to be present in verbatimEventDate, but was not parsed appropriately into day, month, and year, or eventDate. For taxonomic information, names were considered as missing if no genus- or species-level information existed, partial if identified to genus but not to species, and rescuable if not a name listed in at least one taxonomic authority (ornithological authorities checked included
Data on place were considered as missing when geographic coordinates were lacking and textual geographic descriptions lacked information more precise than state. These data were considered as partial when information was available at the level of county/municipality, but not to the level of a specific locality. Data on place were considered as rescuable when the locality was described fully in textual terms, but geographic coordinates missing, or when geographic coordinates were not completely documented with appropriate metadata (
To provide a broader perspective on these data leaks, beyond single datasets, we included overview information parallel to the information for individual datasets for two major, large-scale biodiversity information networks. Specifically, we assessed the Brazilian Virtual Herbarium (5,547,394 records as of 17 February 2017) and VertNet (19,623,087 records as of 17 February 2017). Queries by the information managers of these two networks (authors on this paper) replicated the single-collection analyses described above, to create broad-scale overviews of information completeness across two massive information portals.
For all of the data sets described above, data were summarized in terms of usability for time, taxon, and place separately. We also considered two common applications of primary biodiversity data records. First, for ecological niche modeling and species distribution modeling, a researcher requires information on place and taxon (
Data resources
All data analyzed in this study are freely and openly available via online data resources, particularly from VertNet and GBIF. Specific working datasets are available as Suppl. material
Results
Of the three dimensions of the data that we assessed (time, taxon, and place; Figs


Summary of patterns of completeness and incompleteness of information for 8 herbarium collections, in terms of time, taxon, place, taxon x place, and time x taxon x place. Note that, for lack of a global plant names list that is fully available, we considered rescuable and full taxonomic information together here.

Summary of data leaks in time, place, and taxon information for two major biodiversity informatics initiatives: the Brazilian Virtual Herbarium and VertNet. Note that, for Brazilian Virtual Herbarium, county-level automated georeferencing was included as full georeferencing because it includes information on datum and coordinate uncertainty, although those data records could be georeferenced more finely based on the specific collecting locality. Color scheme follows the key of Figs
We examined data readiness for use in ecological niche modeling and biodiversity inventory analysis (Figs
Discussion
The analyses presented herein showed that all of the datasets examined suffered some amount of leakage or attrition. That is, for diverse reasons, some information got lost along the way. In some cases, the information loss had occurred at the time of collection of the specimen: i.e., a key data field was not recorded. In such situations, the data record may remain forever without that information. In other cases, however, information loss occurred later, such that some potential exists for rescue and recovery of the information. This potential for rescue with intelligent analysis and hard work is illustrated for the case of date information in a recent analysis (
In cases in which the data record may be incomplete, but the data are rescuable, possibilities exist for rapid improvement of DAK resources. For specimen-based biodiversity records, almost always, the specimen can be reexamined and reassessed, perhaps even using new techniques such as DNA barcoding (
Place information is clearly the dimension in which the greatest need for data rescue exists; that is, biodiversity records almost always hold some spatial information, but the translation of that information into carefully derived and documented geographic coordinates is a complex process (
Indeed, some exploration of place-related data leakage patterns is in order. Of the total of 1,011,708,052 records available via the GBIF data portal as of 22 July 2018, 921,414,317 have geographic coordinates. This total of 91.1% georeferenced is impressive, but is also somewhat deceptive—that is, in the first place, most of those georeferenced records do not include the full metadata to document uncertainty (especially coordinateUncertaintyInMeters), even though this information is crucial to applications such as ecological niche modeling (
A further consideration is the interaction between time and data leakage. That is, the specimen record generally is seen as providing the deepest-time view into biodiversity distributions, yet data leakage certainly is more frequent as the age of the specimen increases, as has been documented in previous analyses (
Finally, dimensions of leakage exist that may not be so important for assuring use of the data record. That is, most uses of biodiversity information focus on time, place, and taxon, so other data fields may be less crucial to use of the data in actual analysis; although still important, data sharing and use do not have to await full checking of the full set of fields, as the need for access to such information is immediate and crucial (
Conclusions: the role of e-infrastructures
The explorations presented in this paper lead us to a series of insights into how the field of biodiversity informatics can best move forward towards maximizing its information resources. That is, just investing enormous effort may not be the optimal way forward: rather, “smart” effort may yield much greater pay-offs. Analysis of data leakage, as has been illustrated above, offers ways of thinking about these strategies.
If the goal is to maximize the availability of DAK for analysis and interpretation, one can take into account the sequence of information flow and data leakage (Fig.
This insight can guide time investment in biodiversity informatics initiatives. Analyses such as those we have developed identify immediately the limiting dimensions of DAK usability, thereby focusing immediate investments of time and energy. The clearest signal from our analyses is that detailed and well-documented georeferencing is a crucial aspect of biodiversity informatics, although particular situations can and will differ significantly from this generality. Other insights derive from the data flow and leakage analogy: some biodiversity informatics activities—although important clearly—may not pay off in usable information as immediately. For instance, basic digitization is a major emphasis in the field, and is important for collections management, but digitization in an institutional framework that does not foster data sharing will not improve and increase the availability of information for science and policy.
In previous analyses and assessments of biodiversity data in biodiversity information portals around the world, the concept of Digital Accessible Knowledge has been proposed and explored (
Finally, these data leakage phenomena are not in any way unique to specimen-based biodiversity data. Observation-based biodiversity data, which are becoming massively numerous, have their own leaks, such as misidentifications, which create irreparable problems in records; observational data, nonetheless, may not suffer from some of the major leaks that affect specimen data, such as inconsistent taxonomies, given controlled vocabularies in data entry portals. Recent years have seen the assembly of large-scale data resources from heterogeneous sources: e.g., GenBank, and GLOBIS-B. These data infrastructures must reconcile different formats and norms, which at times results in some data records being unusable or less useful in particular analyses. As such, data leakage is not unique to biodiversity data, but rather a general consequence of data sets becoming large.
Acknowledgements
We thank most fundamentally the biodiversity science community for its large-scale and increasing commitment to sharing openly the important data resources that they have developed over years, decades, and centuries. Luis Osorio Olvera and Ali Khalighifar provided invaluable help with processing large data sets. The idea for this manuscript started at a workshop at Entebbe in Uganda funded by the JRS Biodiversity Foundation, which we thank for its continued support in the area of biodiversity informatics.
Author contributions
All authors contributed to data analysis. ATP drafted the manuscript, which was then edited and commented by all authors.
Conflicts of interest
The authors declare that they have no conflicts of interest.
References
- Data fitness for use in distribution modelling: Are species occurrence data in global online repositories fit for modeling species distributions? The case of the Global Biodiversity Information Facility (GBIF).Global Biodiversity Information Facility,Copenhagen.
- Approaches to estimating the universe of natural history collections data.Biodiversity Informatics7:81‑92.
- Species diversity and distribution in presence-absence matrices: Mathematical relationships and biological implications.American Naturalist172:519‑532. https://doi.org/10.1086/590954
- Completeness of digital accessible knowledge of the plants of Ghana.Biodiversity Informatics11:1‑11.
- The nature and value of ecosystem services: An overview highlighting hydrologic services.Annual Review of Environment and Resources32:67‑98. https://doi.org/10.1146/annurev.energy.32.031306.102758
- Guide to Best Practices for Georeferencing.Global Biodiversity Information Facility,Copenhagen,80pp.
- The Clements Checklist of Birds of the World.6th Edition.Cornell University Press,Ithaca.
- Estimating terrestrial biodiversity through extrapolation.Philosophical Transactions of the Royal Society of London B335:101‑118. https://doi.org/10.1098/rstb.1994.0091
- VertNet: A new model for biodiversity data sharing.PLoS Biology8:e1000309. https://doi.org/10.1371/journal.pbio.1000309
- How many species are there? Revisited.Conservation Biology5:330‑333. https://doi.org/10.1111/j.1523-1739.1991.tb00145.x
- Biodiversity data obsolescence and land uses changes.PeerJ4:e2743. https://doi.org/10.7717/peerj.2743
- Content assessment of the primary biodiversity data published through GBIF network: Status, challenges and potentials.Biodiversity Informatics8:94‑172.
- Completeness of Digital Accessible Knowledge of plants of Benin and priorities for future inventory and data discovery.Biodiversity Informatics11:23‑29.
- Science Review 2016.Global Biodiversity Information Facility,Copenhagen.
- IOC World Bird List (v 6.3).International Ornithological Congresshttps://doi.org/10.14344/IOC.ML.6.3
- BioGeomancer: Automated georeferencing to map the world's biodiversity data.PLoS Biology4:e381. https://doi.org/10.1371/journal.pbio.0040381
- Location, location, location: Utilizing pipelines and services to more effectively georeference the world's biodiversity data.BMC Bioinformatics10:3. https://doi.org/10.1186/1471-2105-10-S14-S3
- Correlative and mechanistic models of species distribution provide congruent forecasts under climate change.Conservation Letters3:203‑213. https://doi.org/10.1111/j.1755-263X.2010.00097.x
- Endemic vertebrates are the most effective surrogates for identifying conservation priorities among Brazilian ecoregions.Diversity and Distributions13:389‑396. https://doi.org/10.1111/j.1472-4642.2007.00345.x
- An audit of some processing effects in aggregated occurrence records.ZooKeys2018:129‑146. https://doi.org/10.3897/zookeys.751.24791
- Five task clusters that enable efficient and effective digitization of biological collections.ZooKeys2012:19‑45.
- On the dates of GBIF mobilised primary biodiversity records.Biodiversity Informatics8(2):173‑184. https://doi.org/10.17161/bi.v8i2.4125
- Check-list of Birds of the World.Vol. 1-16.Harvard University Press,Cambridge.
- Ecological Niches and Geographic Distributions.Princeton University Press,Princeton.
- Mapping Disease Transmission Risk.Johns Hopkins University Press,Baltimore.
- Twentieth century turnover of Mexican endemic avifaunas: Landscape change versus climate drivers.Science Advances1:e1400071. https://doi.org/10.1126/sciadv.1400071
- Digital Accessible Knowledge and well-inventoried sites for birds in Mexico: Baseline sites for measuring faunistic change.PeerJ4:2362. https://doi.org/10.7717/peerj.2362
- The biodiversity data knowledge gap: Assessing information loss in the management of Biosphere Reserves.Biological Conservation173:74‑79. https://doi.org/10.1016/j.biocon.2013.11.020
- DNA Barcoding of Neotropical Sand Flies (Diptera, Psychodidae, Phlebotominae): Species Identification and Discovery within Brazil.PLoS ONE10:e0140636. https://doi.org/10.1371/journal.pone.0140636
- Distribution and Taxonomy of Birds of the World.Yale University Press,New Haven, Connecticut.
- Completeness of Digital Accessible Knowledge of the plants of Brazil and priorities for survey and inventory.Diversity and Distributions20:369‑381. https://doi.org/10.1111/ddi.12136
- A conceptual framework for quality assessment and management of biodiversity data.PloS one12:e0178731.
- Evaluating whether nature's intrinsic value is an axiom of or anathema to conservation.Conservation Biology29(2):321‑332. https://doi.org/10.1111/cobi.12464
- Digital Accessible Knowledge of Kenyan succulent flora and priorities for future inventory and documentation.Biodiversity Informatics11:12‑22.
- The point-radius method for georeferencing locality descriptions and calculating associated uncertainty.International Journal of Geographical Information Science18:745‑767. https://doi.org/10.1080/13658810412331280211
- Biodiversity.National Academies Press,Washington, DC.
Supplementary materials
This file offers detailed responses to two reviewers' comments, which were presented as very long, multipoint comments on the manuscript.
These data are the summaries of data leaks in each of three dimensions for each of the bird and herbarium datasets that are depicted in Figures 2 and 3.
Comma-delimited ASCII data corresponding to specimens held in a series of museum collections
Comma-delimited ASCII data corresponding to herbarium specimens in several collections