|
Biodiversity Data Journal :
Software description
|
A semi-automated workflow for biodiversity data retrieval, cleaning, and quality control
|
Corresponding author:
Academic editor: Lyubomir Penev
Received: 04 Nov 2014 | Accepted: 07 Dec 2014 | Published: 11 Dec 2014
© 2014 Cherian Mathew, Anton Güntsch, Matthias Obst, Saverio Vicario, Robert Haines, Alan Williams, Yde de Jong, Carole Goble
This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation:
Mathew C, Güntsch A, Obst M, Vicario S, Haines R, Williams A, de Jong Y, Goble C (2014) A semi-automated workflow for biodiversity data retrieval, cleaning, and quality control. Biodiversity Data Journal 2: e4221. https://doi.org/10.3897/BDJ.2.e4221
|
|
Abstract
The compilation and cleaning of data needed for analyses and prediction of species distributions is a time consuming process requiring a solid understanding of data formats and service APIs provided by biodiversity informatics infrastructures. We designed and implemented a Taverna-based Data Refinement Workflow which integrates taxonomic data retrieval, data cleaning, and data selection into a consistent, standards-based, and effective system hiding the complexity of underlying service infrastructures. The workflow can be freely used both locally and through a web-portal which does not require additional software installations by users.
Keywords
biodiversity informatics, web services, workflows, service oriented architecture, data cleaning, e-Science
Introduction
Over the last decade, the international biodiversity informatics community has built service-oriented infrastructures that provide constantly updated datasets and computational services supporting the mobilisation (data gathering), compilation (data structuring), contextualization (data standardisation based, for example, on TDWG Biodiversity Information Standards, www.tdwg.org), integration and validation (data cleaning) of species-related occurrence information (
A range of data services and tools have been developed to address data aggregation, cleaning and curation aspects such as Kurator (
Project description
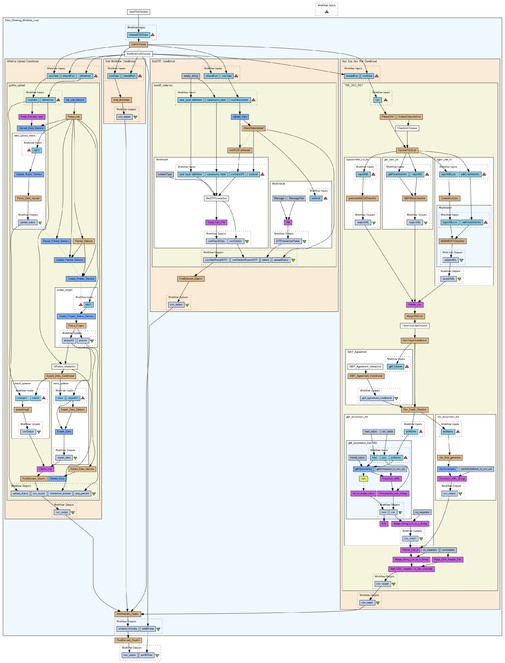
The Taxonomic Data Refinement Workflow integrates a range of services to perform data processing tasks with the possibility of adding new services if required. The workflow accepts species occurrence data, taxon-level data, or a list of scientific names as input, and offers three distinct sub-workflows for particular tasks depending on the input type (Fig.
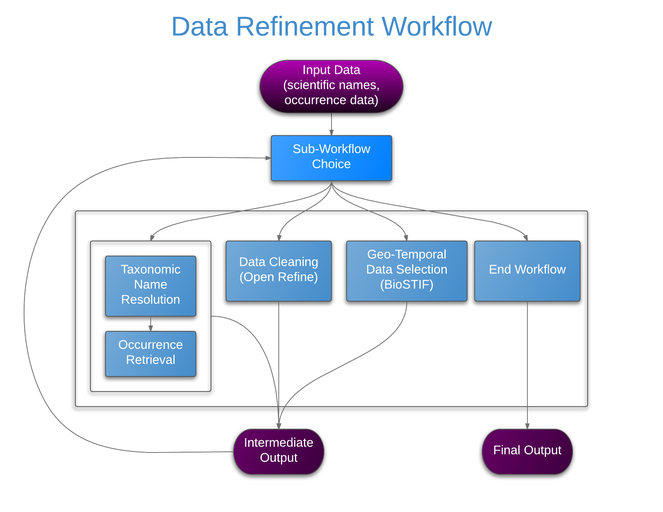
- Taxonomic Name Resolution and Occurrence Retrieval: Scientific names included in the input dataset are submitted to user-selected checklists (Fig.
2 ). Users browse through the respective lists of accepted names and synonymies and choose names that will be added to the original input list. Users then retrieve species occurrence records from selected occurrence data services and the retrieved datasets are then added to the original user data. Depending on how correct, complete and up-to-date the checklist services are, the quality of responses used as a basis for name resolution may vary considerably. The decision on the choice of responses to be included in the resolution process for individual names has to be taken by the user; - Data Cleaning: Cleaning of data records as well as semantic enrichment are conducted using a biodiversity-specific extension of OpenRefine (http://openrefine.org/) (Fig.
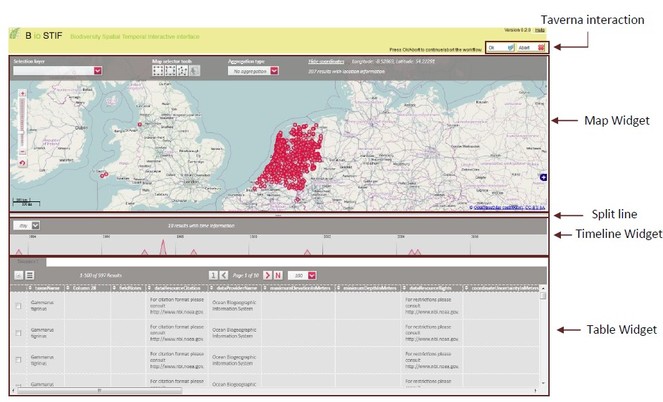
3 ). Typical activities include the mapping of data fields to controlled vocabularies (standardised taxonomies), resolving nomenclatural variations, and supporting the identification and exclusion of erroneous or irrelevant records. Targeted checklists can be selected at different stages of the name resolution process (Fig.6 ); - Geo-Temporal Data Selection: Users filter records in time and space using the BioSTIF system (https://wiki.biovel.eu/display/doc/BioSTIF+User+Manual) which offers an interactive GIS-like interface for selecting records by drawing polygons on a map and by defining time slices (Fig.
4 ).
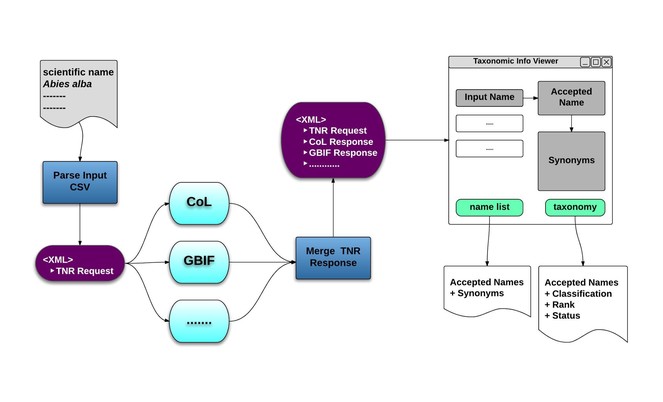
Taxonomic Name Resolution. Overview of the Name Resolution function of the Taxonomic Data Refinement Workflow, depicting the aggregation of scientific name responses from the various checklist into a single XML message. This message is then used to display the results within a web interface.
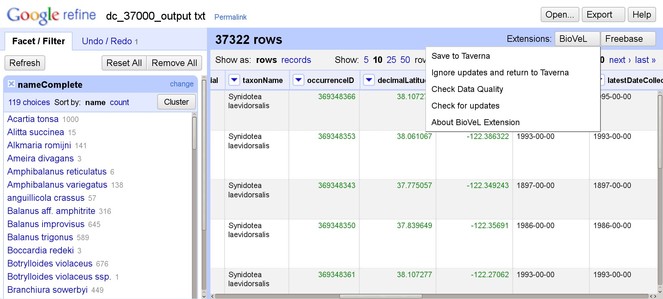
OpenRefine interface with the BioVeL extension. The extension adds biodiversity data specific functionality to OpenRefine for the purposes of data cleaning, integration, and refinement. The GoogleRefine branding in the screenshot is due to the fact this workflow uses the last stable released version (2.5) of OpenRefine when the software was still being developed by Google.
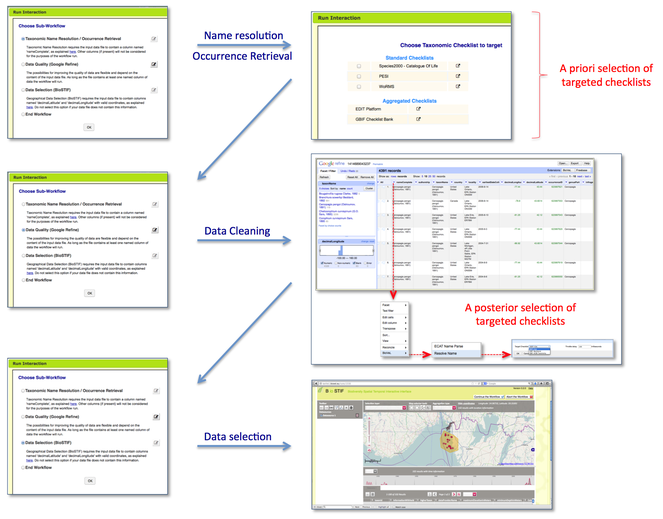
Inputs and outputs of each section are compatible and users may execute sections in any order and as many times as needed, with the option to end the workflow at any point.
Traditionally, workflows are used for automating complex or large-scale data processing tasks, often requiring systematic and multiple analyses over sets of data or parameters. However, the power of the Taxonomic Data Refinement Workflow lies in its flexible access to highly specialized and distributed services without exposing the computational protocols needed to interact with them; and the structuring of the studies into a systematic protocol whose results can be compared, its process documented and the source of the results logged. The seamless integration of these service functions enables scientists to inspect large biodiversity data sets simultaneously from different angles (e.g. taxonomic, geographic, ecological), and this integrated view allows for appropriate data selection that leads to the generation of comparable data sets.
The workflow has been constructed using Taverna Workbench (http://www.taverna.org.uk/download/workbench/) by progressively building each section using individual modules called ‘services’. A number of frequently used services are already available within the workbench environment and developers are encouraged to build their own specific services using Beanshell scripting (http://jcp.org/en/jsr/detail?id=274). This allows for the creation of complex analysis pipelines connecting various local and remote services and nested workflows. Once constructed, the workflows are reusable executable biodiversity informatics protocols that can be shared, reused and repurposed. One of the main features of the workflow is the web browser-based interaction inspired by the development of the Interaction plugin (http://www.taverna.org.uk/documentation/taverna-2-x/interaction) for the Taverna environment. The browser-based approach opens up the possibility of running the workflow on Taverna Player (http://www.taverna.org.uk/documentation/taverna-2-x/taverna-player), a remote execution environment with web-based interactions, which eliminates the requirement to download and install any local software components. This implies that the workflow can be executed both locally and within a remote server environment.
Workflow complexity
Converting the conceptual idea of the workflow into an automated form has revealed the complexity inherent in combining various kinds of services, both local and remote, each with their own input parameters and output formats. (Fig.
Workflow design
Workflow input format: The workflow accepts input data from a user supplied CSV (http://tools.ietf.org/html/rfc4180) file, with controlled header terms referring to concepts defined by TDWG LSID Vocabularies (http://wiki.tdwg.org/twiki/bin/view/TAG/LsidVocs). These vocabularies, in particular the TaxonName (http://wiki.tdwg.org/twiki/bin/view/TAG/TaxonNameLsidVoc) and TaxonOccurrence (http://wiki.tdwg.org/twiki/bin/view/TAG/TaxonOccurrenceLsidVoc) subset have been chosen because they represent a set of well documented vocabularies (https://wiki.biovel.eu/display/doc/Preparing+your+input+data+for+Data+Refinement) defined for common concepts in the biodiversity informatics domain. Records in the CSV input file must at least consist of either,
- a list of taxonomic names made up of TaxonName information
- a set of occurrence observation records comprising both TaxonName and TaxonOccurrence information.
The decision to support only the CSV format with a restricted set of header terms has kept the development effort focused on quickly adding various functionality to the workflow rather than making the workflow compatible with different types of existing input formats and vocabularies. This decision implies that the input data preparation for the workflow needs to be done by the user. However, by keeping the format simple and limiting the number of terms, manual intervention is minimized. Future versions of the workflow will support additional data input formats, which can be transformed into a normalized format using transformation software such as Pentaho Kettle (http://sourceforge.net/projects/pentaho/).
Taxonomic name resolution and species occurrence retrieval: Resolving names to taxonomic concepts is one of the most crucial functionalities of the workflow (
- Catalogue of Life (CoL;
Roskov et al. 2014 ; www.catalogueoflife.org/), - Global Biodiversity Information Facility Checklist Bank (GBIF; http://www.gbif.org/species),
- EDIT Platform for Cybertaxonomy (EDIT;
Berendsohn 2010 ; http://cybertaxonomy.eu/cdmlib/rest-api-name-catalogue.html), - World Register of Marine Species (WoRMS, http://www.marinespecies.org/), and
- Pan-European Species directories Infrastructure (PESI, http://www.eu-nomen.eu/portal/).
with more planned for the future. The response from each of these web service calls is converted to XML form and appended to the corresponding request. The final representation can be then visualized in a viewer, which displays the relationship between names and their corresponding taxonomic concepts, with the possibility of extracting specific information. Currently the options include the generation of a de-duplicated list of accepted names and their synonyms as well as a list of accepted names along with corresponding taxonomic information.
The option to retrieve occurrence records of species obtained as a result of name resolution is also provided within this section of the workflow. Currently the only target is the GBIF Occurrence API (http://www.gbif.org/occurrence), which provides a single access point to more than 500 million distributed occurrence records. Additional targets, equipped with a standardized service interface, can be included as per requirements.
This workflow section provides an interface for functionality related to taxonomic data aggregation and this aspect can be greatly improved in the future. For instance, the name resolution section works only with exact name matches and does not provide any kind of reconciliation feature which most experts may consider as a crucial requirement. Another feature that would make the workflow more efficient is to expose specific data provider options to the user, e.g. allowing the user to select geographical bounds to the occurrence data requested from providers like GBIF which offer this kind of capability.
Taxonomic Data Cleaning: The quality of taxonomic data and species occurrence records plays an important role in biodiversity analysis. Given that loss of data quality could occur in any of the multiple stages of data collection, it is of utmost importance that the data retrieved from the various sources be ‘fit for use’ in relation to the study undertaken (
- Data Quality Checks: This includes a global quality check on specific elements of the dataset (e.g. validity of latitude / longitude values, date validation, etc).
- Data Transformation: This set of features allow for the conversion of data into a form which is fit for purpose (e.g clustering scientific names using name parsers, conversion of data units, etc.).
- Data Extension: This category of features makes it possible to enrich existing data by using local and remote services (e.g. resolving scientific names to their accepted names, reverse geo-referencing, etc.).
Following initial investigations on the feasibility of building such an environment based on existing solutions, it was decided to use OpenRefine. In addition to the intuitive interface with the various faceted views to edit data, the ability to extend functionality was a crucial factor in the decision. This has led to the implementation of the BioVeL Extension which integrates custom-made functionality, third-party libraries and remote services to provide features which cover the three categories mentioned above. OpenRefine along with the BioVeL Extension also shows considerable potential in other use cases such as the cleaning of taxonomic data prior to upload into managed databases as well as playing a role in the annotation of already existing data. All data processing activities can be recorded in JSON format for re-use on different data sets or as a data processing log (www.ietf.org/rfc/rfc4627.txt)
Geo-Spatial / Temporal Data Selection: This section of the workflow deals with the selection of data based on geographical regions as well as the filtering of records with respect to time-based information. The selection is performed using the geo-server based, web-enabled, GIS application BioSTIF (www.biodiversitycatalogue.org/services/7). The tool allows the user to filter in/out occurrence data points by constructing polygonal regions using the given toolbox. A temporal range can also be selected by using the timeline tool to choose a specific period of interest. Along with these functionalities the tool also provides a tabular view of the data.
The workflow in use
The Data Refinement Workflow has been used in a number of scientific studies including
- Leidenberger S, De Giovanni R, Kulawik R, Williams AR, Bourlat SJ (2014) Mapping present and future potential distribution patterns for a meso-grazer guild in the Baltic Sea (http://onlinelibrary.wiley.com/enhanced/doi/10.1111/jbi.12395/)
- Laugen et al (In Review) The Pacific Oyster (Crassostrea gigas) invasion in Scandinavian coastal waters in a changing climate: impact on local ecosystem services. In Biological Invasions in Aquatic and Terrestrial Systems: Biogeography, Ecological Impacts, Predictions, and Management. De Gruyter, Warsaw.
- Leidenberger S, Obst M, Kulawik R, Stelzer K, Heyer K, Hardisty A, Bourlat SJ (In Review) Evaluating the potential of ecological niche modelling as a component in invasive species risk assessments. Ecological Applications.
User access and documentation
The full workflow documentation (Data Refinement Workflow v.13) as well as an extensive tutorial is available at https://wiki.biovel.eu/display/doc/Data+Refinement+Workflow. The workflow can be downloaded from myExperiment under http://www.myexperiment.org/workflows/2874/versions/16.html, and executed through the BioVeL portal under http://portal.biovel.eu. Web-service documentations are accessible from the BiodiversityCatalogue (https://www.biodiversitycatalogue.org/).
Outlook
The Data Refinement Workflow presented in this paper is a generic approach to provide tools to end users working with biodiversity data. The solution presented here has been developed as an automated workflow and tackles problems related to the aggregation, cleaning and geo-temporal selection of data. Even though such tools have been traditionally developed by data service providers, in most cases these can be applied only to data specific to the providers. The DRW aims to enable users to aggregate and normalise data from various sources and then work on making the data fit-for-purpose for a target research use case.
The development of such kinds of workflows to be used in conducting in-silico experiments has exposed a number of technical issues. Firstly, it is becoming increasingly clear that a certain level of software expertise is required to develop automated workflows and efforts should be made to ease the technical burden on users (primarily scientists) who may not be so proficient in software development. For example, in its current form the Data Refinement Workflow restricts input data to the CSV format using controlled vocabularies, but should definitely allow for other formats (e.g. TSV, XML, etc) if the workflow approach is to be widely adopted.
The workflow has already been used in scientific research use cases which have greatly benefited from the use of the functionality and the efficiency provided by the workflow approach. Future work should include studies to quantify the level of benefit for the users and consider benchmarking the workflow approach as a whole and individual components in particular using well described metrics, which allow for a more objective view on how the DRW compares to other existing tools.
The design and implementation of the Data Refinement Workflow was funded by the EU’s Seventh Framework Program project BioVeL (www.biovel.eu) with the grant no. 283359.
Web location (URIs)
Usage rights
Author contributions
Cherian Mathew and Anton Güntsch designed and implemented the workflow. Matthias Obst and Yde de Jong contributed specifications based on real-world scientific applications and conducted several tutorial workshops for scientists. Robert Haines, Alan Williams and Carole Goble designed and built the workflow execution environment. All authors contributed to the preparation of the manuscript.
References
- Berendsohn WG (2010) Devising the EDIT Platform for Cybertaxonomy. In: Nimis PL, Vignes Lebbe R (Eds) Tools for identifying biodiversity: progress and problems.1-6pp. [ISBN978-88-8303-295-0].
- Biodiversity information platforms: From standards to interoperability.ZooKeys150:71‑87. https://doi.org/10.3897/zookeys.150.2166
- Principles and methods of data cleaning – primary species and species occurrence data.1.0.Global Biodiversity Information Facility. URL: http://www.gbif.org/orc/?doc_id=1262
- Kurator: A Kepler Package for Data Curation Workflows.Procedia Computer Science9:1614‑1619. https://doi.org/10.1016/j.procs.2012.04.177
- Effectively searching specimen and observation data with TOQE, the Thesaurus optimized Query Expander.Biodiversity Informatics6:53‑58.
- Species 2000 & ITIS Catalogue of Life.29th October 2014.Species 2000: Naturalis, Leiden, the Netherlands. URL: www.catalogueoflife.org/col
- The Taverna workflow suite: designing and executing workflows of Web Services on the desktop, web or in the cloud.Nucleic Acids Research41:W557‑W561. https://doi.org/10.1093/nar/gkt328